


| | Tekststrenge |
Dette kapitel handler om ordning og lighed mellem strenge.
|
28.1. Leksikografisk ordning af strenge
Indhold Op Forrige Næste Slide Aggregerede slides Stikord Programindeks Opgaveindeks
En ordning af tekststrenge kan afledes af ordningen blandt de tegn, som tekststrengen er bygget op af. I dette afsnit diskuterer vi ordningen af tekststrenge på det generelle plan, uafhængig af C.
Ordningen af tegn inducerer en ordning af tegnstrenge (tekststrenge) Den normale alfabetiske ordning af tekststrenge spiller en vigtig rolle ved opslag i leksika, telefonbøger, mv. Vi vil her definere hvad det betyder af strengen s er mindre end strengen t |
Herunder definerer vi betydningen af at en streng s er mindre end en streng t.
|
Der er to tilfælde i definitionen. Første tilfælde siger at den tomme streng er mindre end enhver ikke-tom streng.
Det andet tilfælde har to undertilfælde, som begge udtaler sig om to ikke-tomme strenge s og t. Det første undertilfælde siger at s < t hvis første tegn i s er mindre end første tegn i t. Det andet undertilfælde siger at hvis første tegn i s er lig med første tegn i t, afgøres vurderingen s < t rekursivt af u < v, hvor u er halen af s og v er halen af t.
Lad os se på nogle eksempler. De følgende fire udsagn er alle sande.
Det første tilfælde forklares ved at 'A' < 'H'.
Det andet tilfælde argumenteres ganske tilsvarende, nemlig ved at 'a' < 'k'.
I det tredje tilfælde skræller vil tegnene 'a', 'b', og 'e' af begge strenge og vurderer dermed "hat" i forhold til "kat".
I det sidste tilfælde skræller vi også tegnene 'a', 'b', og 'e' af begge strenge og vurderer den tomme streng "" i forhold til "kat".
28.2. Lighed af strenge (1)
Indhold Op Forrige Næste Slide Aggregerede slides Stikord Programindeks Opgaveindeks
I dette afsnit ser vi på et eksempel, som generelt illustrerer at lighed mellem to ting kan have flere forskellige betydninger.
Lighed mellem skalartyper (specielt aritmetiske typer), jf. afsnit 18.1, volder sjældent problemer. Lighed mellem sammensatte typer, såsom arrays og strenge, kan have flere forskellige betydninger.
Den lære vi drager i dette afsnit for strenge kan generaliseres til andre sammensatte datastrukturer, f.eks. lister (afsnit 41.1) og records/structs (kapitel 39).
Der er to mulige fortolkninger af lighed af to strenge s og t |
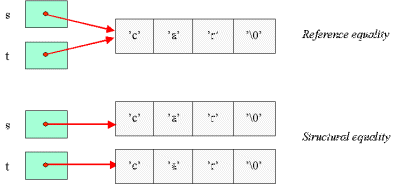
| Figur 28.1 En illustration af reference lighed og strukturel lighed mellem char * variable |
|
Hvis to strenge er reference ens er de også strukturelt ens, men ikke nødvendigvis omvendt |
Ovenstående observation følger naturligt ved at se på figur 28.1. Hvis to strenge s og t er reference ens vil det naturligvis være tilfældet at tegnene i s og t er parvis ens. Hvis derimod to strenge s og t er strukturelt ens, kan vi ikke sluttet at s og t udpeges af identiske pointere.
28.3. Funktionen strcmp fra string.h
Indhold Op Forrige Næste Slide Aggregerede slides Stikord Programindeks Opgaveindeks
Funktionen strcmp fra standard biblioteket i C er nyttig i forbindelse med vurdering af leksikografisk ordning og strukturel lighed når vi programmerer i C.
Functionen strcmp fra string.h implementerer den leksikografiske ordning samt strukturel lighed på tekststrenge i C |
|
Det vil ofte give bedre programmer hvis vi vurderer to strenge med en funktion, som giver et boolsk (true/false) resultat. Med sådanne kan vi skrive string_leq(s,t) i stedet for strcmp(s,t) == -1. Og i en selektiv kontrolstruktur kan man skrive
if (string_equal(s,t))
...
else
...i stedet for
if (strcmp(s,t) == 0)
...
else
...Hvis vi ønsker funktioner ala string_leq og string_equal må vi selv programmere dem, hvilket naturligvis er ganske enkelt.
Vi kender ikke de konkret returværdier af et kald af strcmp. Returværdien er altså implementationsafhængig. Dette illustreres klart i program 28.2. Men ideen om at signalere mere end blot "mindre end", "lig med" og "større end" gennem mere nuancerede værdier ses ofte. I vores tilfælde afspejler den returnerede talværdi forskellen mellem de to tegn, som adskiller tekststrengene.
Programmet herunder, program 28.1, viser eksempler på leksikografisk ordning målt med strcmp.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | #include <stdio.h>
#include <string.h>
void pr(char*, char*, int);
int main(void) {
int b1 = strcmp("book", "shelf");
int b2 = strcmp("shelf", "book");
int b3 = strcmp("","book");
int b4 = strcmp("book","bookshelf");
int b5 = strcmp("book", "book");
int b6 = strcmp("7book", "book");
int b7 = strcmp("BOOK", "book");
pr("book", "shelf", b1);
pr("shelf", "book", b2);
pr("", "book", b3);
pr("book", "bookshelf", b4);
pr("book", "book", b5);
pr("7book","book", b6);
pr("BOOK", "book", b7);
return 0;
}
void pr(char *s, char *t, int r){
printf("strcmp(\"%s\",\"%s\") = %i\n", s,t,r);
} | |||
|
Output fra program 28.1 kan ses i program 28.2.
1 2 3 4 5 6 7 | strcmp("book","shelf") = -17
strcmp("shelf","book") = 17
strcmp("","book") = -98
strcmp("book","bookshelf") = -115
strcmp("book","book") = 0
strcmp("7book","book") = -43
strcmp("BOOK","book") = -32 | |||
|
| Genereret: Onsdag 7. Juli 2010, 15:12:15 | |